Results at a glance
Headline numbers from the two SPECA papers, gathered in one place. Each chart links to the detailed reproduction recipe under Operations.
RQ1 — Sherlock Ethereum Fusaka audit contest
Setup. 10 production Ethereum clients implementing EIP-7594 / EIP-7691 (Go / Rust / Nim / TypeScript / C / C#). Ground truth: 15 valid H/M/L issues out of 366 contest submissions.
How much does the 3-gate filter help?
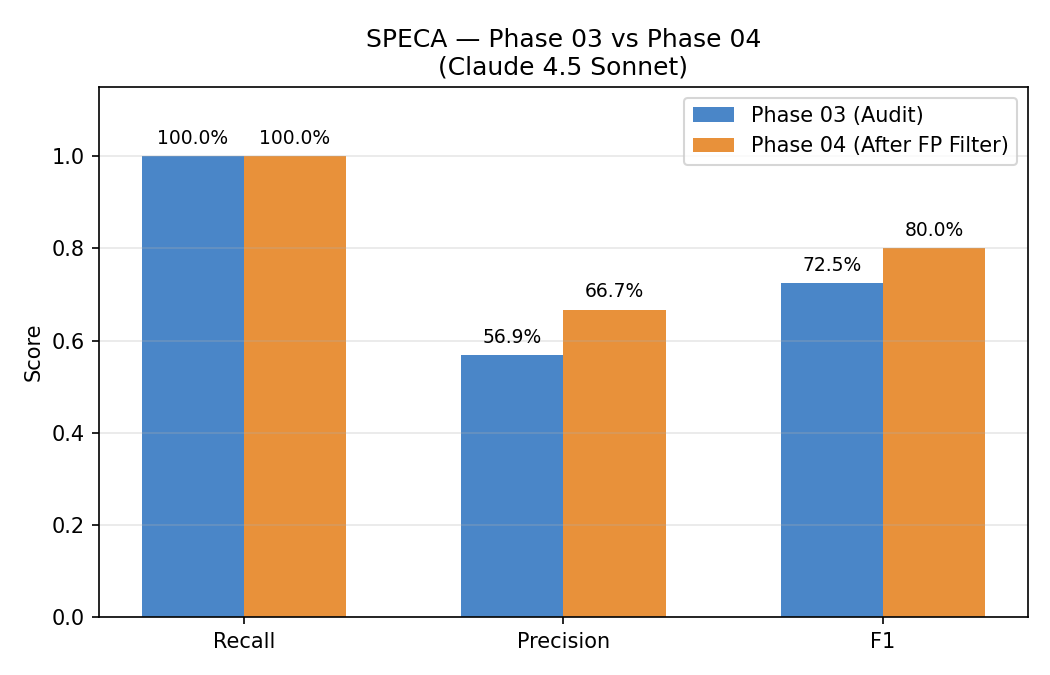
Recall is held at 100% across both stages — that is the recall-safe design in action. Precision rises from 56.9% → 66.7% and F1 from 0.725 → 0.800. See 3-Gate review for why the gates are ordered Dead Code → Trust Boundary → Scope.
Per-gate verified-FP rate
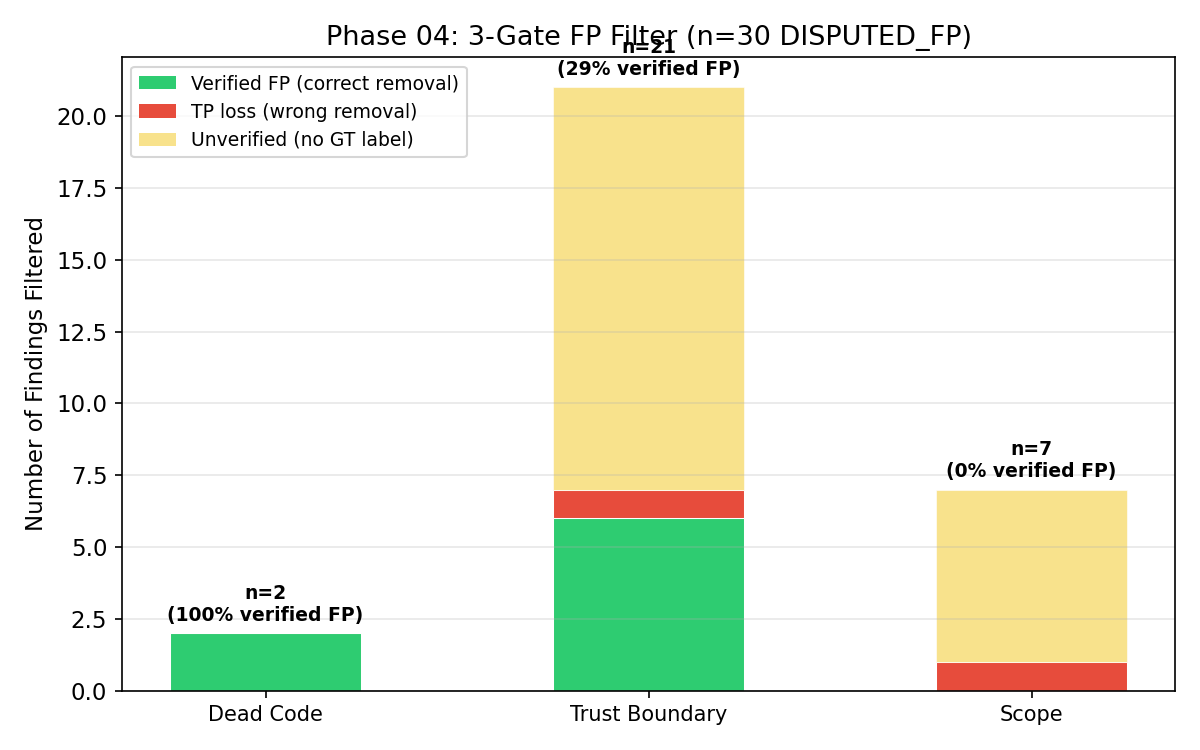
The Dead Code gate has the cleanest signal (n=2, 100% verified FP). The Trust Boundary gate carries most of the volume (n=21) and the Scope gate handles the long tail. Yellow bars are findings the ground truth does not label, so they remain "unverified."
Where do remaining false positives come from?
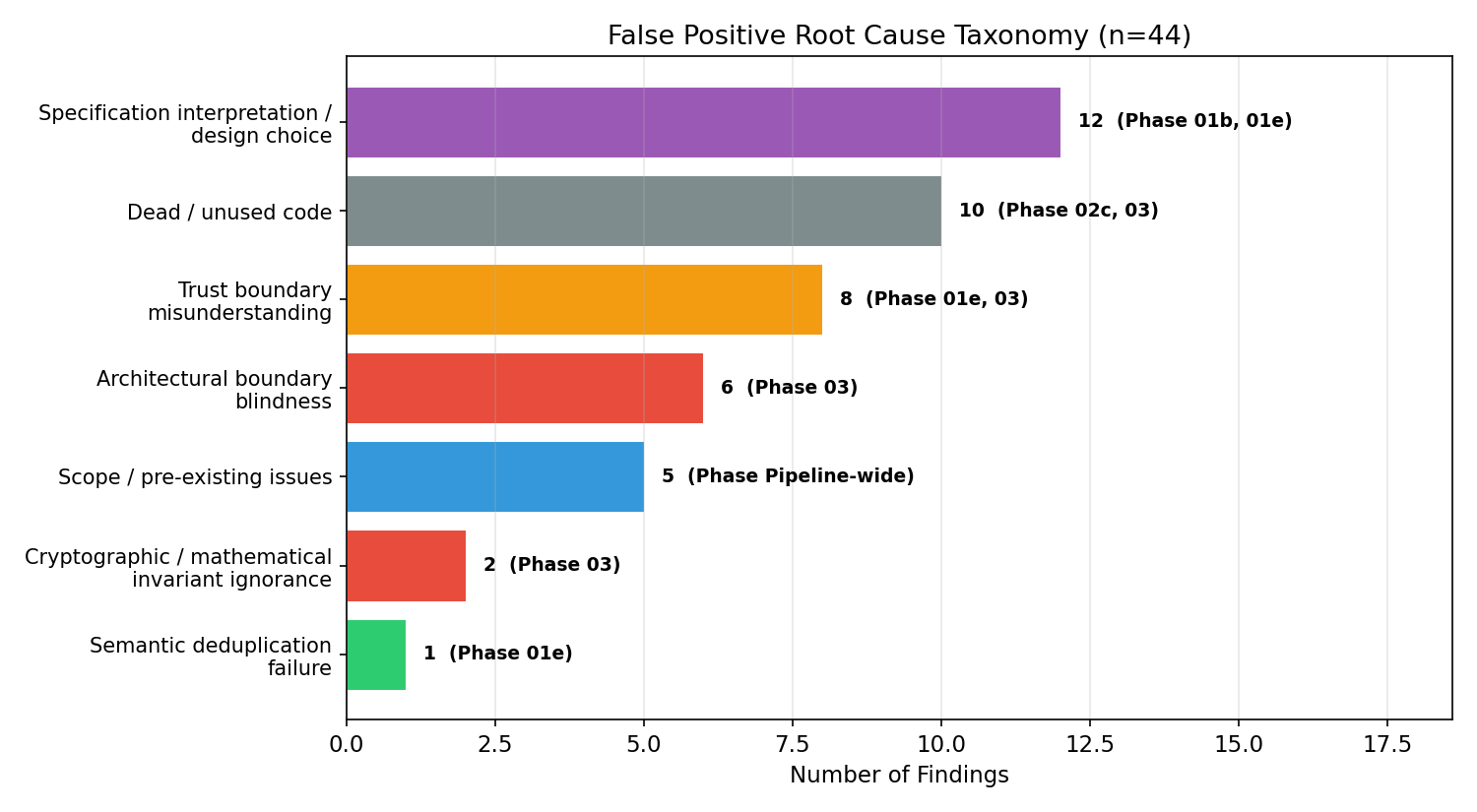
44 false positives, broken down by root cause and tagged with the phase responsible. The largest class — Specification interpretation / design choice (12) — points back to Phases 01b/01e, not the verification phases. This is the empirical basis for the design note that property-generation quality, not back-end model strength, binds coverage.
RQ2a — RepoAudit C/C++ benchmark (15 OSS projects)
Setup. ICML 2025 RepoAudit benchmark, 251K LoC average per project, 35 + 5 adjudicated bugs.
Precision vs. published baselines
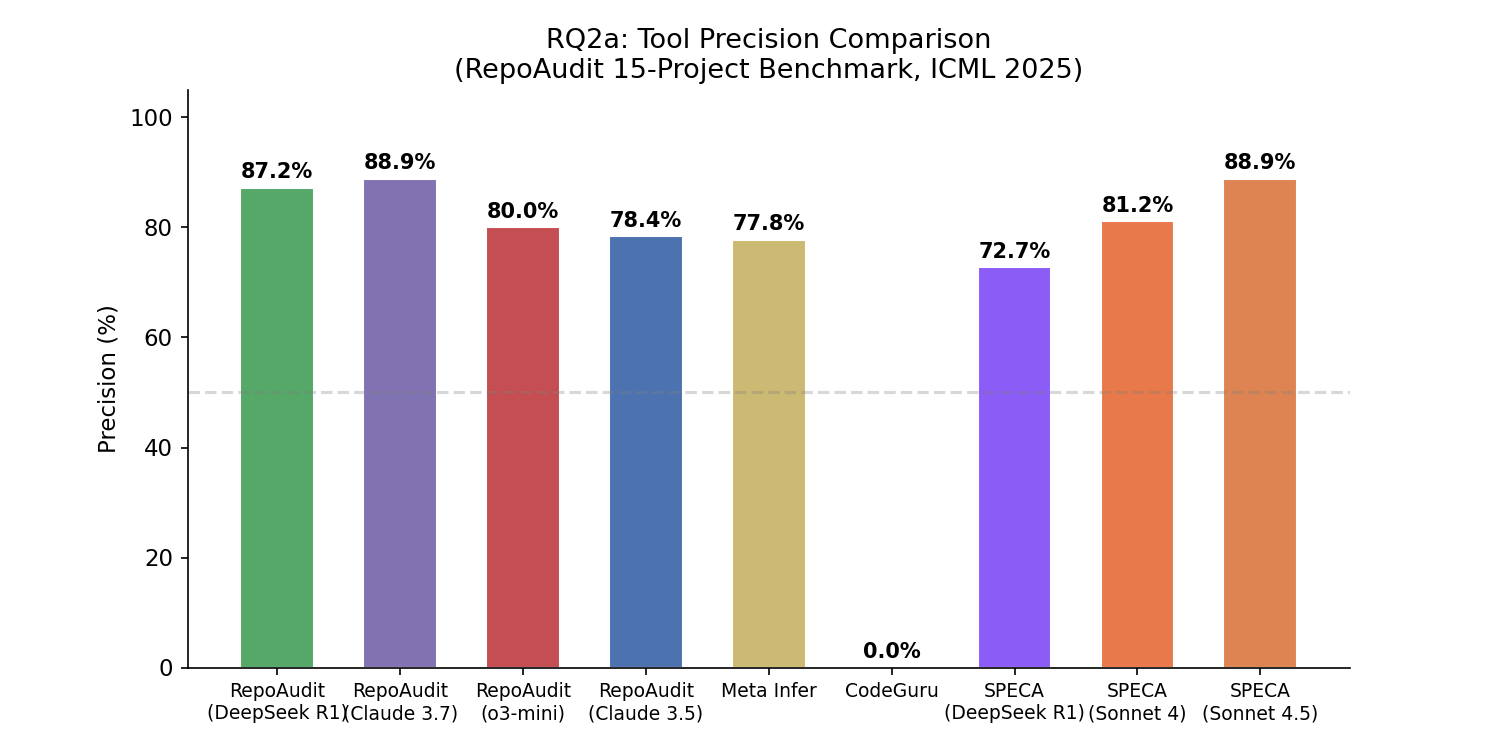
SPECA + Sonnet 4.5 ties the highest published baseline at 88.9%. The static-analysis baselines (Meta Infer 77.8%, CodeGuru 0.0%) and the lightest LLM tier (o3-mini 80.0%) sit below.
Cost vs. detection performance
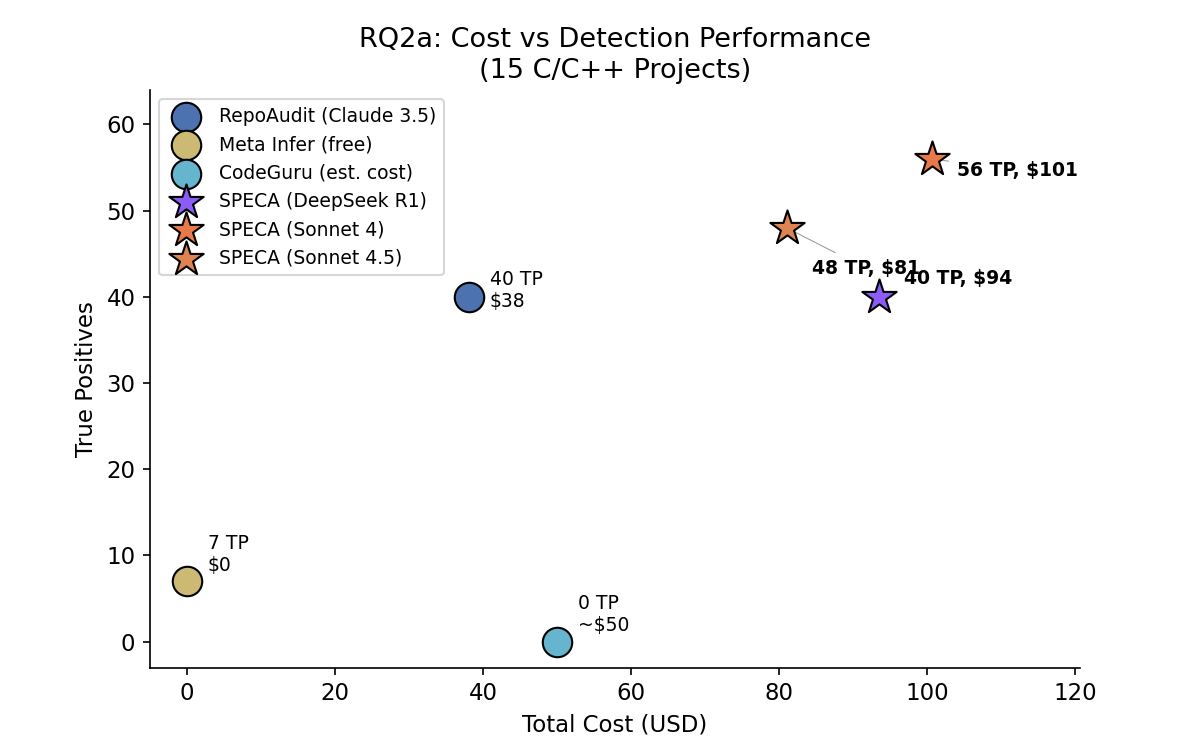
Sonnet 4.5 reaches 56 TPs at $101. Sonnet 4 sits at 48 TPs / $81 (the precision/coverage tradeoff is discussed in the model-benchmark design note). DeepSeek R1 lands at 40 TPs / $94, with a noticeably stricter dismissal style.
Numbers in one row
| Benchmark | Recall | Precision | F1 | Notable |
|---|---|---|---|---|
| Sherlock Fusaka (15 H/M/L) | 15/15 (expert-augmented) · 8/15 (auto) | 66.7% (broad) | 0.800 | 4 novel bugs missed by 366 auditors |
| RepoAudit C/C++ (35 + 5) | 100% on known set | 88.9% | 0.94 | 12 author-validated beyond-GT candidates · ~$1.69 / bug |
Reproduction commands and tagged release artifacts: Operations.