Pipeline overview
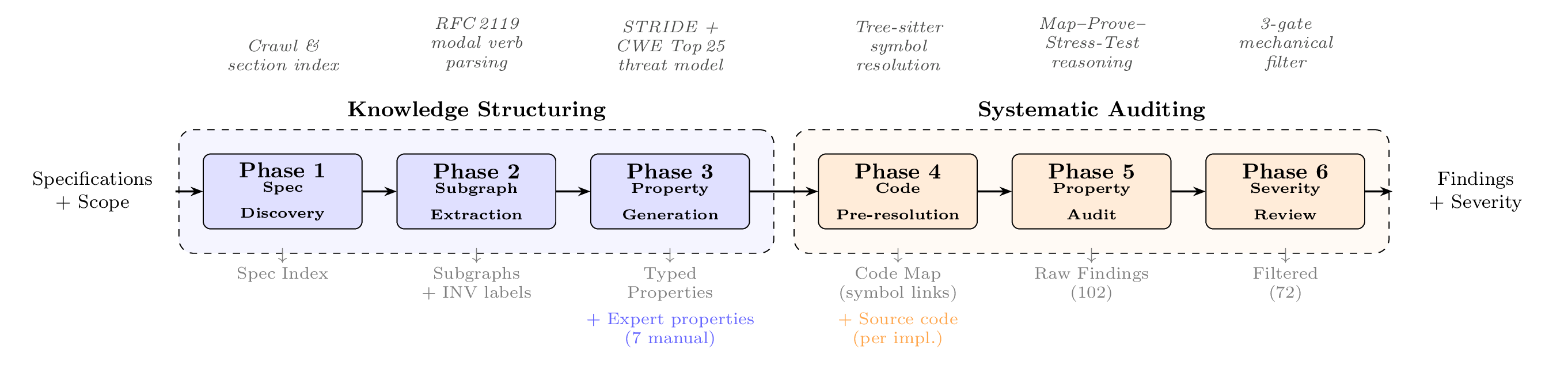
SPECA is a six-stage pipeline. The first three stages convert a specification into typed properties (Knowledge Structuring); the last three audit those properties against an implementation (Systematic Auditing).
Phase numbering — paper vs. internal IDs
The two SPECA papers number the stages Phase 1–6. The codebase uses internal IDs that reflect the original development order (01a, 01b, 01e, 02c, 03, 04). Both refer to the same stages:
| Paper | Internal ID | Plain-English name | Page |
|---|---|---|---|
| Phase 1 | 01a | Spec Discovery | 01a |
| Phase 2 | 01b | Subgraph Extraction | 01b |
| Phase 3 | 01e | Property Generation | 01e |
| Phase 4 | 02c | Code Pre-resolution | 02c |
| Phase 5 | 03 | Property Audit (Map / Prove / Stress-Test) | 03 |
| Phase 6 | 04 | Severity Review (3-gate FP filter) | 04 |
The CLI and orchestrator everywhere use the internal IDs (e.g. speca run --target 04).
Dependency chain
01a (Spec Discovery)
↓
01b (Subgraph Extraction)
↓
01e (Property Generation) ← BUG_BOUNTY_SCOPE.json required
↓
02c (Code Pre-resolution) ← TARGET_INFO.json required
↓
03 (Audit Map: Map → Prove → Stress-Test)
↓
04 (Review: Dead Code → Trust Boundary → Scope)
The first three phases (01a / 01b / 01e) depend only on the specification and the scope rubric — they can be run once and cached across implementations. The last three (02c / 03 / 04) depend on the target codebase and run per implementation.
Inputs and outputs
| ID | Name | Input | Output |
|---|---|---|---|
| 01a | Spec Discovery | SPEC_URLS env | 01a_STATE.json |
| 01b | Subgraph Extraction | 01a_STATE.json | Mermaid .mmd + 01b_PARTIAL_*.json |
| 01e | Property Generation | Subgraphs + STRIDE/CWE Top 25 | 01e_PARTIAL_*.json |
| 02c | Code Resolution | Properties + source | 02c_PARTIAL_*.json |
| 03 | Audit Map | Properties + code | 03_PARTIAL_*.json |
| 04 | Review | Phase 03 findings | 04_PARTIAL_*.json (six verdicts) |
Data flow conventions
- Partial files:
outputs/<phase_id>_PARTIAL_W{worker}B{batch}_{timestamp}.json - Queue files:
outputs/<phase_id>_QUEUE_{worker}.json - Logs:
outputs/logs/{phase_id}_*.jsonl
Each phase consumes upstream partial files via glob patterns, skips already-processed items (resume), and writes results immediately after each batch — partial progress is never blocked on validation.
Cross-cutting harness features
The orchestrator provides four features that apply to every phase. They are described in detail under Agent design — Harness:
- Circuit Breaker — shared across all workers in a phase. Trips on consecutive failures, total retries, or repeated empty results.
- Cost Tracker — per-phase USD budget; raises
BudgetExceededand hard-stops the phase when crossed. - Resume Manager — scans
*_PARTIAL_*.jsonto identify already-processed items so re-runs skip them by default. - Log Watcher — tails the stream-json log in real time and forwards events to the TUI dashboard.
For the model assignment per phase and the prompt / skill split, see Prompts and skills.