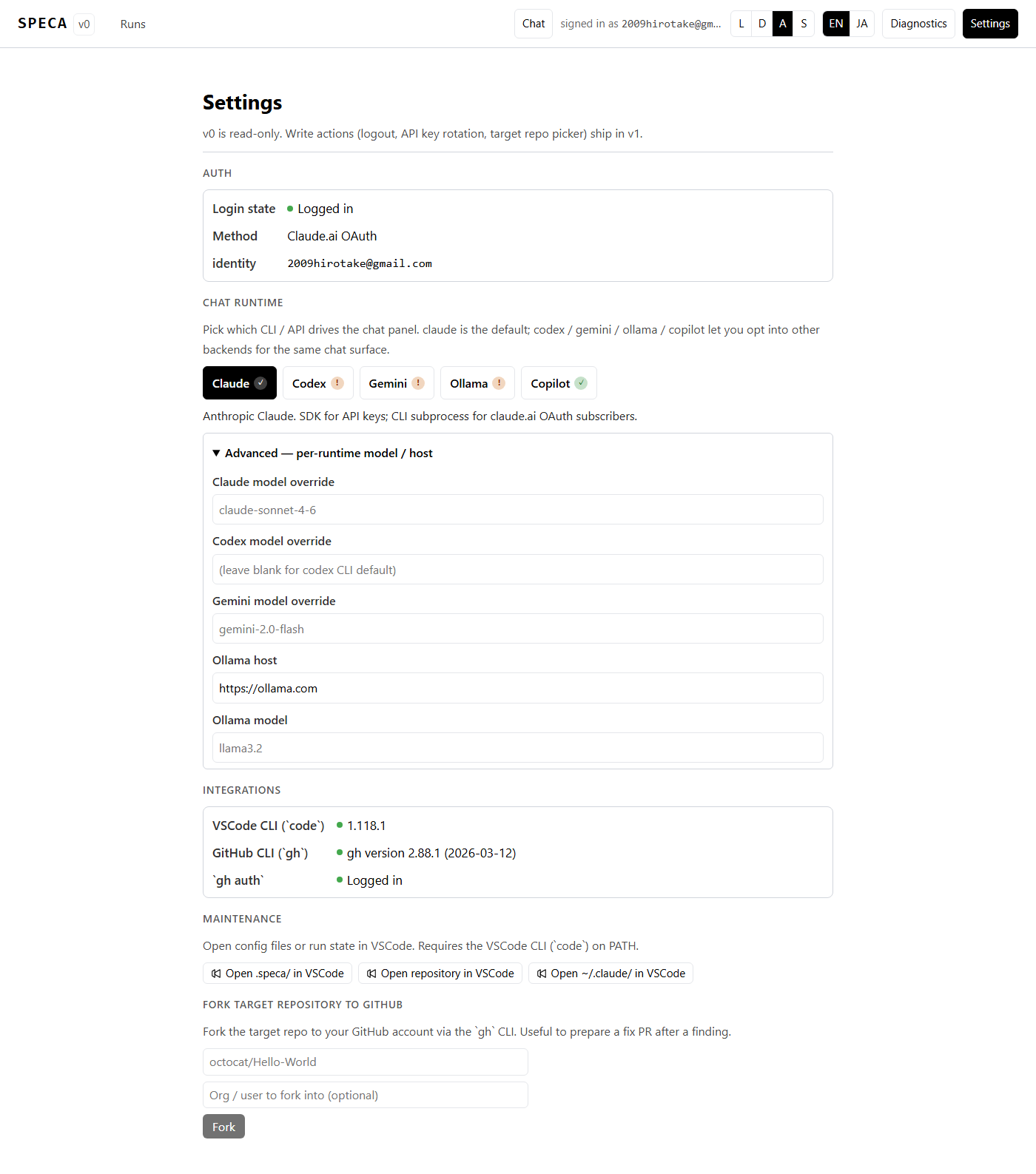
Multi-runtime backends
SPECA supports claude / codex / gemini / ollama / copilot plus a
generic api (OpenRouter-style) backend — 6 backends in total. The
chat panel and the audit pipeline each accept a runtime selector,
chosen in Settings or via an env var.
:::tip Positioning
SPECA is a CLI Client — it shells out to each backend's official CLI
/ API. Authentication stays with the backend (claude auth login,
codex login, an API key, …); SPECA only owns the selection via
Settings or an env var.
:::
Support matrix
| Runtime | Chat panel | Audit pipeline | Auth | Default model |
|---|---|---|---|---|
| claude (default) | ✅ SDK or CLI subprocess | ✅ ClaudeRunner (stream-json + MCP) | ANTHROPIC_API_KEY or claude auth login | claude-sonnet-4-6 |
| api (OpenRouter / etc.) | — | ✅ APIRunner | API_RUNNER_API_KEY | deepseek/deepseek-r1 |
| codex | ✅ codex exec --json | ✅ CodexAPIRunner (APIRunner subclass) | codex login or OPENAI_API_KEY | gpt-4o |
| gemini | ✅ gemini -p --output-format stream-json | ✅ GeminiAPIRunner (OpenAI-compat endpoint) | GEMINI_API_KEY | gemini-2.0-flash |
| ollama | ✅ HTTP /api/chat | ✅ OllamaAPIRunner (<host>/v1/chat/completions) | OLLAMA_API_KEY (cloud) / none (self-hosted) | llama3.2 |
| copilot | ✅ @github/copilot agentic CLI | ✅ CopilotRunner (subprocess + JSONL events) | GitHub OAuth on first copilot launch | CLI default (override via COPILOT_MODEL) |
Per-backend deep dive
Claude (default)
Anthropic Claude. In the chat panel, API-key users go through the SDK
and claude.ai OAuth subscribers (Pro/Max) go through the claude CLI
subprocess. The audit pipeline uses ClaudeRunner with stream-json +
MCP tree-sitter for full feature support.
npm install -g @anthropic-ai/claude-code
claude auth login # claude.ai OAuth (Pro/Max) or API key
OAuth tokens are stored in ~/.claude/.credentials.json. To use an
API key instead, either export ANTHROPIC_API_KEY or paste it into
the Web UI login screen.
Pro / Max + Web UI integration: Login can be completed end-to-end in the browser via the paste-code OAuth flow:
See CLI spec §4.5.1 + Web UI features for details.
Codex (OpenAI)
Via the official codex CLI for chat, or OPENAI_API_KEY directly
for audit. The CLI works with either a ChatGPT plan subscription or an
API key:
npm install -g @openai/codex
# Use a ChatGPT plan
codex login
# Or an API key
printenv OPENAI_API_KEY | codex login --with-api-key
Chat side (working today):
Spawns codex exec --json as a subprocess. --resume <session_id>
keeps multi-turn context. Tools are restricted to --sandbox read-only.
Audit pipeline side:
Does NOT need the codex CLI installed — CodexAPIRunner (an APIRunner
subclass) talks to https://api.openai.com/v1 directly with
OPENAI_API_KEY, reusing the existing Read / Grep / Glob / Write tool
loop unchanged.
| Env var | Default | Purpose |
|---|---|---|
OPENAI_API_KEY | (required) | API authentication |
OPENAI_MODEL | gpt-4o | Model id |
OPENAI_BASE_URL | https://api.openai.com/v1 | Endpoint override (Azure OpenAI etc.) |
Gemini (Google)
Via the gemini CLI for chat, or Google's OpenAI-compatible
endpoint for audit:
npm install -g @google/gemini-cli
export GEMINI_API_KEY=... # https://aistudio.google.com/apikey
Chat side:
Spawns gemini -p <prompt> --output-format stream-json --approval-mode plan. The plan approval mode pins read-only behaviour
so the chat panel is safe. The tolerant parser accepts several
stream-json event shapes (text / delta / content /
candidates.content.parts[].text).
Audit pipeline side:
GeminiAPIRunner targets
https://generativelanguage.googleapis.com/v1beta/openai/chat/completions.
Function-calling is fully compatible with OpenAI's wire format, so the
APIRunner loop just works.
| Env var | Default | Purpose |
|---|---|---|
GEMINI_API_KEY | (required) | API authentication |
GEMINI_MODEL | gemini-2.0-flash | Model id (gemini-2.5-pro, etc.) |
GEMINI_BASE_URL | https://generativelanguage.googleapis.com/v1beta/openai | Endpoint override |
Ollama (cloud + self-hosted)
Self-hosted:
ollama serve # localhost:11434
ollama pull llama3.2
export OLLAMA_HOST=http://localhost:11434
# OLLAMA_API_KEY not required for local
Cloud:
export OLLAMA_HOST=https://ollama.com
export OLLAMA_API_KEY=... # https://ollama.com
Chat side:
Talks HTTP /api/chat with NDJSON streaming via httpx.AsyncClient.
The last 20 turns of conversation history are replayed each request
(Ollama is stateless).
Audit pipeline side:
Uses Ollama's OpenAI-compatible endpoint at
<host>/v1/chat/completions. OllamaAPIRunner derives base_url
from OLLAMA_HOST, so self-hosted (http://localhost:11434/v1) and
cloud (https://ollama.com/v1) work identically.
| Env var | Default | Purpose |
|---|---|---|
OLLAMA_HOST | https://ollama.com | Host (cloud or self-hosted) |
OLLAMA_API_KEY | (cloud: required) | Bearer token (cloud only) |
OLLAMA_MODEL | llama3.2 | Model id (llama3.2:70b, etc.) |
OLLAMA_BASE_URL | Derived from OLLAMA_HOST | Endpoint override |
:::info Self-hosted Ollama cost
APIRunner's cost_tracker reads usage off the OpenAI-compatible
response, so self-hosted Ollama reports total_cost_usd = 0 (local
inference, no per-token charge) — expected.
:::
GitHub Copilot
Backed by the @github/copilot agentic CLI. Chat and audit pipeline
both drive the same CLI via subprocess.
npm install -g @github/copilot
copilot # First launch performs GitHub OAuth (creds in ~/.copilot)
Chat side:
Spawns copilot -p <prompt> --output-format json --allow-all-tools --no-banner as a subprocess and converts the JSONL events into SSE
frames for the client. tool_use events still go through the circuit
breaker and approval gate. The older gh copilot suggest shim was
retired in PR #73.
Audit pipeline side:
CopilotRunner (scripts/orchestrator/copilot_runner.py) drives the
CLI in the same JSONL mode and feeds session.* / assistant.delta /
tool.* / error / complete events into an accumulator. Tool
execution stays inside the CLI (--allow-all-tools), so unlike
APIRunner we do not need Python-side Read/Grep/Glob/Write executors.
| Env var | Default | Purpose |
|---|---|---|
COPILOT_MODEL | (CLI default) | Pass through as --model <id> |
:::info Cost tracking
When a usage event carries input_tokens / output_tokens we feed
the CostTracker (gpt-4o-class rate as a conservative estimate). Copilot
is a flat-rate subscription, so when the CLI omits usage we leave
total_cost_usd=0 — same convention as self-hosted Ollama.
:::
api (OpenRouter / DeepSeek / any OpenAI-compat)
Generic OpenAI-compatible HTTP runner. Point at any endpoint via
API_RUNNER_BASE_URL:
export API_RUNNER_API_KEY=sk-or-v1-...
export API_RUNNER_BASE_URL=https://openrouter.ai/api/v1
export API_RUNNER_MODEL=deepseek/deepseek-r1
Audit pipeline only (not used by the chat side).
Pick a runtime from the CLI
List availability
uv run python scripts/run_phase.py --list-runtimes
The output shows each backend with its install / auth status:
Active runtime: claude (ORCHESTRATOR_RUNNER env / --runtime flag)
[OK] claude
Anthropic claude CLI (stream-json). Production audit path.
- claude CLI ready.
[..] codex
OpenAI Chat API (codex CLI authenticates against this). Tool-calling enabled.
- Routes through CodexAPIRunner -> https://api.openai.com/v1
- OPENAI_MODEL: gpt-4o
- Set OPENAI_API_KEY to authenticate.
[OK] copilot
GitHub Copilot agentic CLI (`copilot -p --output-format json --allow-all-tools`). Tool-calling owned by the CLI.
- copilot CLI on PATH.
- Copilot subscription required.
- Routes through CopilotRunner (subprocess + JSONL events). Set COPILOT_MODEL to override the CLI's default model.
JSON mode (for CI / speca-cli consumers):
uv run python scripts/run_phase.py --list-runtimes --json | python -m json.tool
Choose at run time
# OpenRouter
uv run python scripts/run_phase.py --target 04 --runtime api --workers 4
# codex / gemini / ollama / copilot
uv run python scripts/run_phase.py --target 04 --runtime codex
uv run python scripts/run_phase.py --target 04 --runtime gemini -c model=gemini-2.5-pro
uv run python scripts/run_phase.py --target 04 --runtime ollama
uv run python scripts/run_phase.py --target 04 --runtime copilot
--runtime overrides ORCHESTRATOR_RUNNER. Every registered runtime
is now implemented=True, so there are no stubs to fall back from. If
a future stub gets added (implemented=False), selecting it aborts
with exit 2 instead of silently routing to claude.
Pick a runtime from the Web UI
/settings has a Chat runtime section:
- Five buttons (Claude / Codex / Gemini / Ollama / Copilot) with
(✓)/(!)availability badges - One-line status hint per selected runtime
- Advanced — per-runtime model / host expands to set model / Ollama host overrides
- Persisted to
~/.speca/runtime.json(no secrets)
API keys (OLLAMA_API_KEY / OPENAI_API_KEY / GEMINI_API_KEY) are
read from the server process env at request time — the Settings file
never sees them, so it is safe on shared machines.
Known limits
- Phase 02c (MCP tree-sitter) — only
clauderuns the MCPmcp__tree_sitter__*servers. Other runtimes reduce code pre-resolution accuracy. Workarounds: skip 02c (--phase 01a 01b 01e 03 04), or run 02c under--runtime claudeand the rest under another runtime. - Reproducibility — different models give different findings;
benchmark via
benchmarks/. - Cost tracker — APIRunner reads
usageoff the OpenAI-compatible response, so self-hosted Ollama reportstotal_cost_usd = 0(local inference, no per-token charge). - Copilot also misses MCP — Phase 02c's MCP tree-sitter is
claude-only, so running 02c under
--runtime copilotdrops code-pre-resolution accuracy (same caveat as codex/gemini/ollama). Workarounds: skip 02c (--phase 01a 01b 01e 03 04) or run 02c under claude and the rest under copilot.