結果ハイライト
2 本の SPECA 論文から主要な数字を 1 ページにまとめたものです。各チャートからは、運用ガイド の詳細な再現手順にリンクしています。
RQ1 — Sherlock Ethereum Fusaka 監査コンテスト
設定: EIP-7594 / EIP-7691 を実装する Ethereum クライアント 10 種 (Go / Rust / Nim / TypeScript / C / C#)。グラウンドトゥルースは 366 件の投稿のうち有効と認定された H/M/L 15 件。
3 ゲートのフィルタはどれだけ効いているか
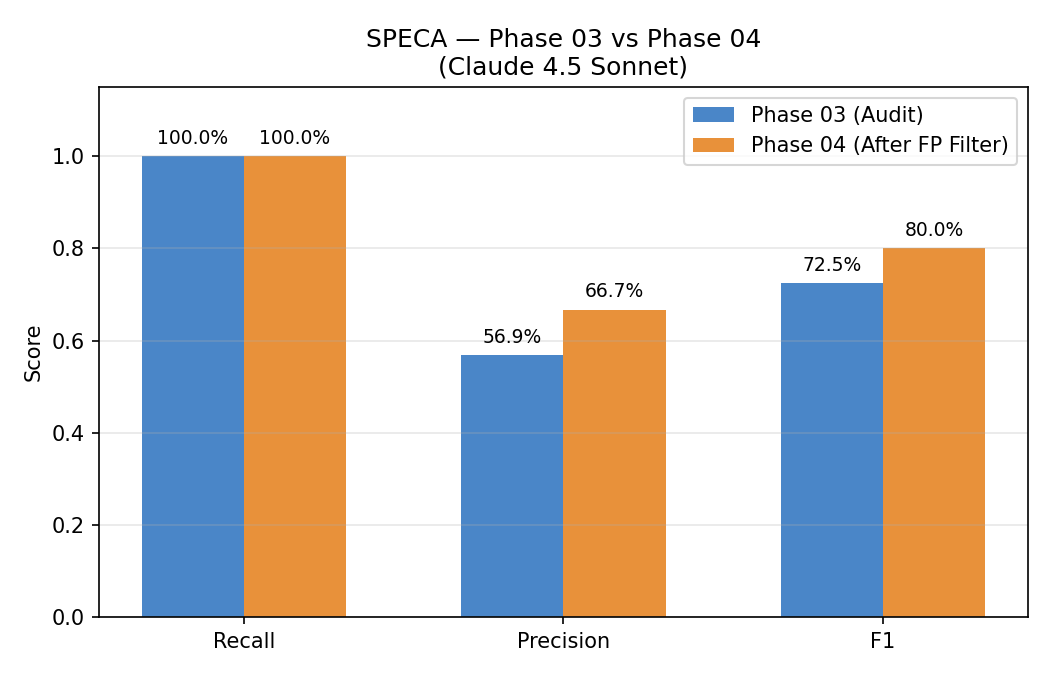
Recall は両ステージで 100% を維持 — これが recall-safe 設計の実証です。Precision は 56.9% → 66.7%、F1 は 0.725 → 0.800 へ改善しています。Dead Code → Trust Boundary → Scope の順序を選んだ理由は 3 ゲートレビュー を参照してください。
ゲート別の検証済み FP 率
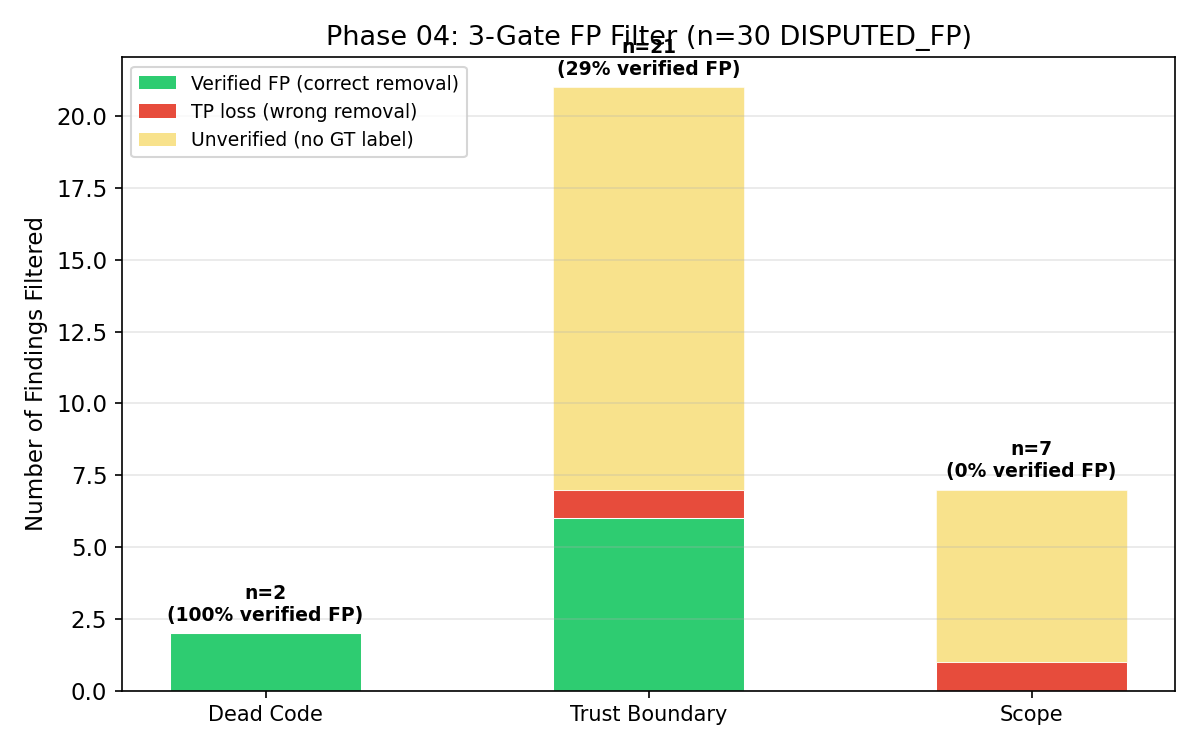
Dead Code ゲートは最も判定がクリーン (n=2 / 100% verified FP)。Trust Boundary がボリュームの大半を担い (n=21)、Scope は残りのロングテールを処理します。黄色のバーはグラウンドトゥルースにラベルがない findings で、検証不能 (unverified) として残ります。
残存する FP の根本原因
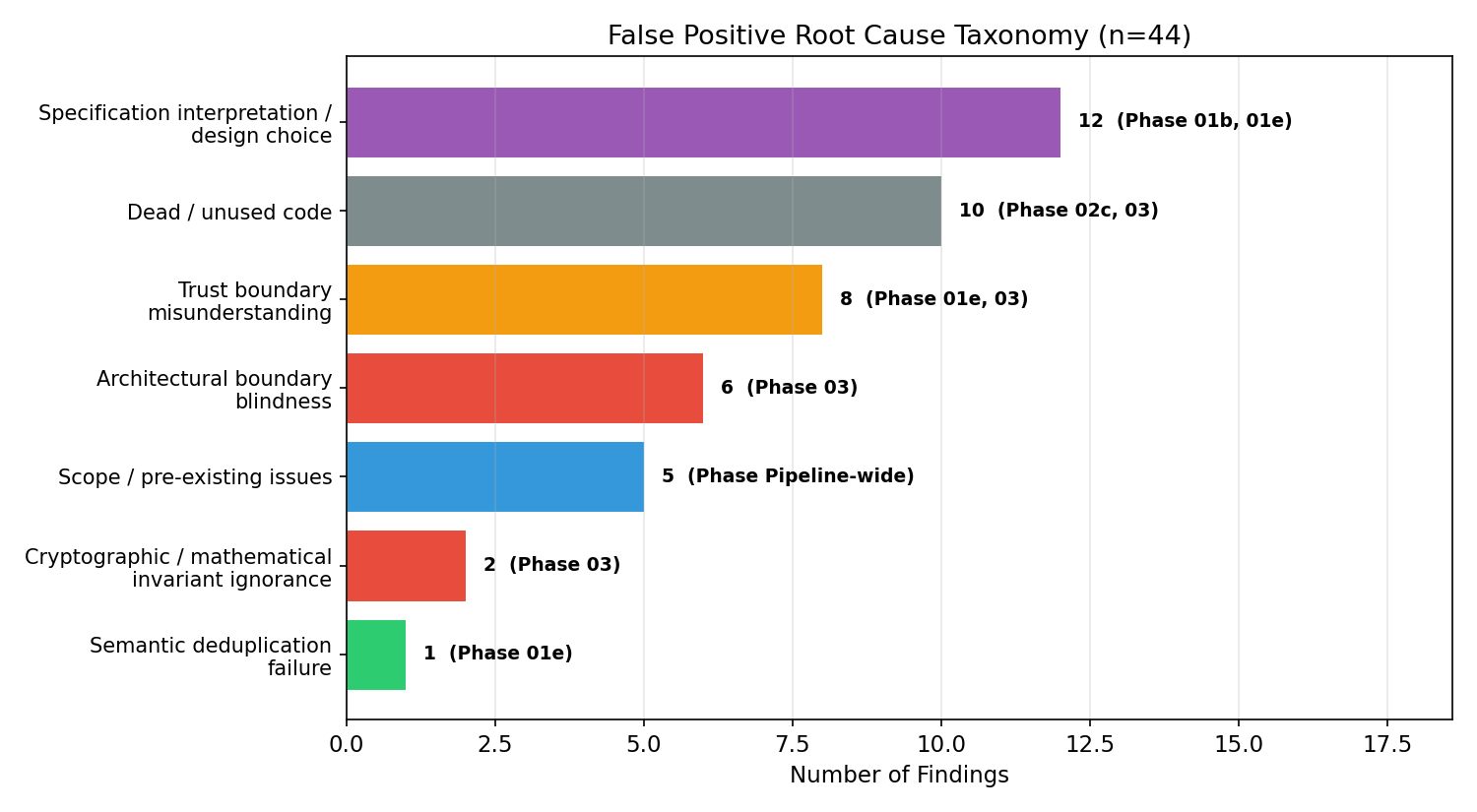
44 件の FP を根本原因別に分類し、責任のあるフェーズをラベル付けしたチャートです。最大のクラス Specification interpretation / design choice (12 件) は Phase 01b/01e に起因しており、検証側のフェーズではありません。これは「カバレッジを縛るのは後段モデルの強さではなく プロパティ生成品質である」という設計ノートの実証データになっています。
RQ2a — RepoAudit C/C++ ベンチマーク (15 OSS プロジェクト)
設定: ICML 2025 RepoAudit ベンチマーク。プロジェクトあたり平均 251K LoC、認定済みバグは 35 + 5 件。
Precision と公開ベースラインの比較
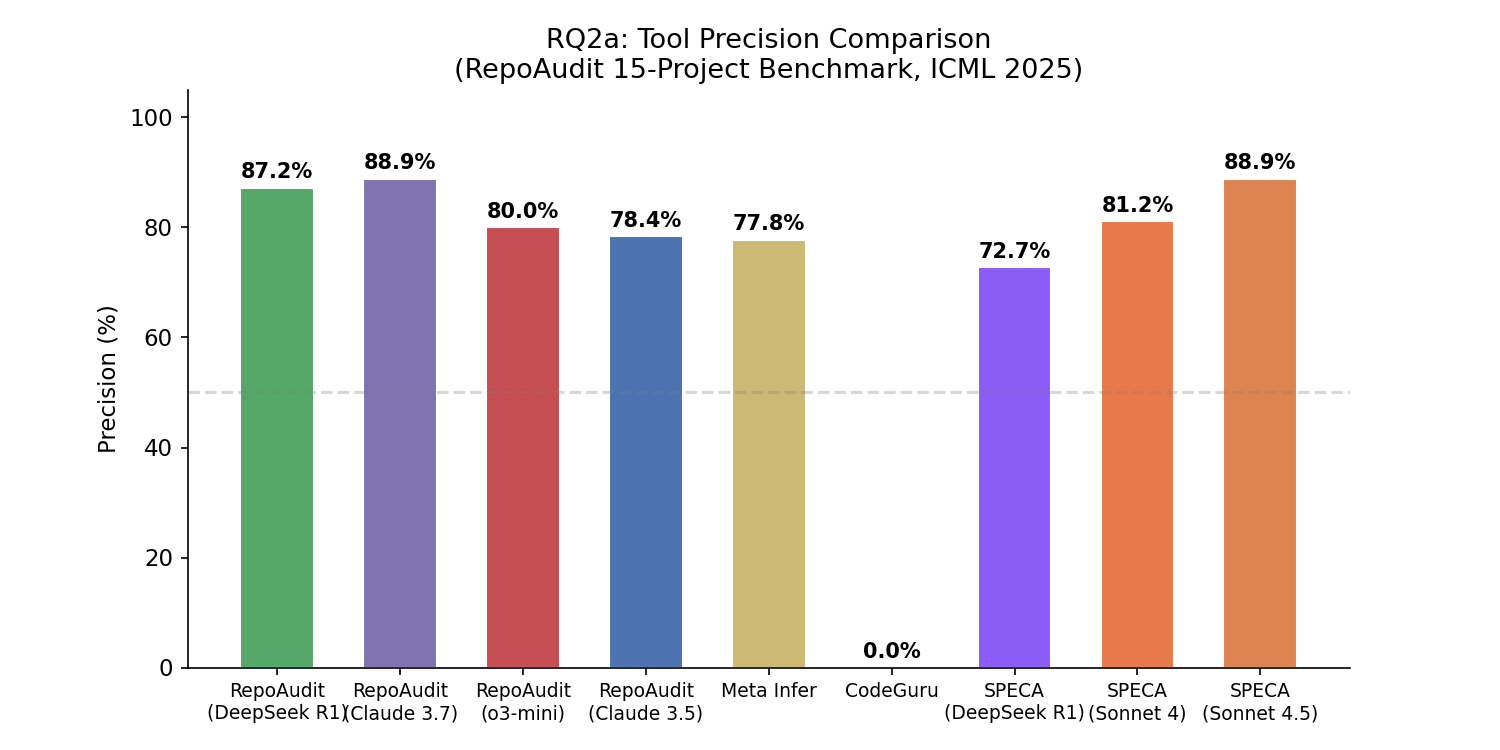
SPECA + Sonnet 4.5 は最高公開ベースラインに並ぶ 88.9%。静的解析ベースライン (Meta Infer 77.8% / CodeGuru 0.0%) と最軽量 LLM 系 (o3-mini 80.0%) はその下に並びます。
コスト vs 検出性能
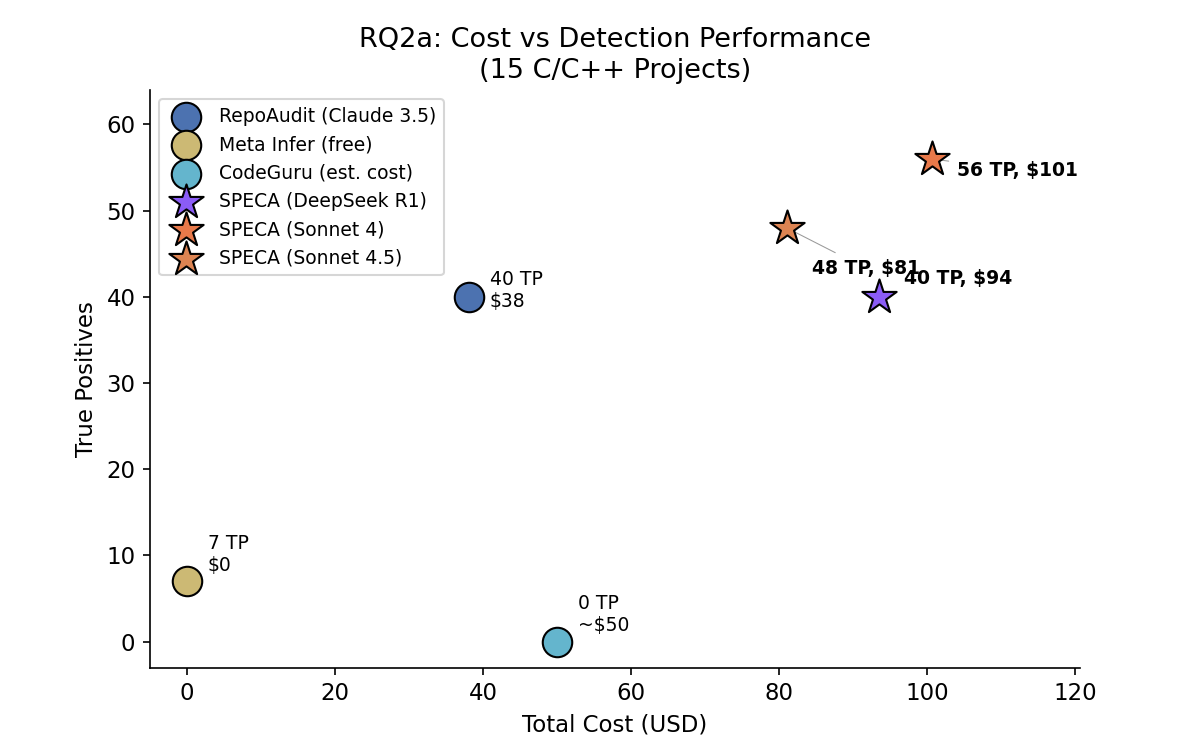
Sonnet 4.5 は $101 で 56 TP。Sonnet 4 は 48 TP / $81 (precision とカバレッジのトレードオフは モデル選定の設計ノート を参照)。DeepSeek R1 は 40 TP / $94 で、明確に厳しめの dismissal スタイルが現れます。
数字を 1 行で
| ベンチマーク | Recall | Precision | F1 | 特筆点 |
|---|---|---|---|---|
| Sherlock Fusaka (15 H/M/L) | 15/15 (expert-augmented) · 8/15 (auto) | 66.7% (broad) | 0.800 | 366 名の監査者が見落とした新規バグ 4 件 |
| RepoAudit C/C++ (35 + 5) | 既知集合に対して 100% | 88.9% | 0.94 | 著者検証済みの GT 外候補 12 件 · 約 $1.69 / バグ |
再現コマンドとリリースタグの紐付け: 運用ガイド。