どうやって動く?
SPECA は 6 つの段階 (Phase) を順に実行します。ここでは各段階を日本語で説明してから、内部での技術的な名前を紹介します。
1 つのプロパティが全 6 段を通る様子をリアルな JSON 例で追うなら ワークドエグザンプル を見てください。
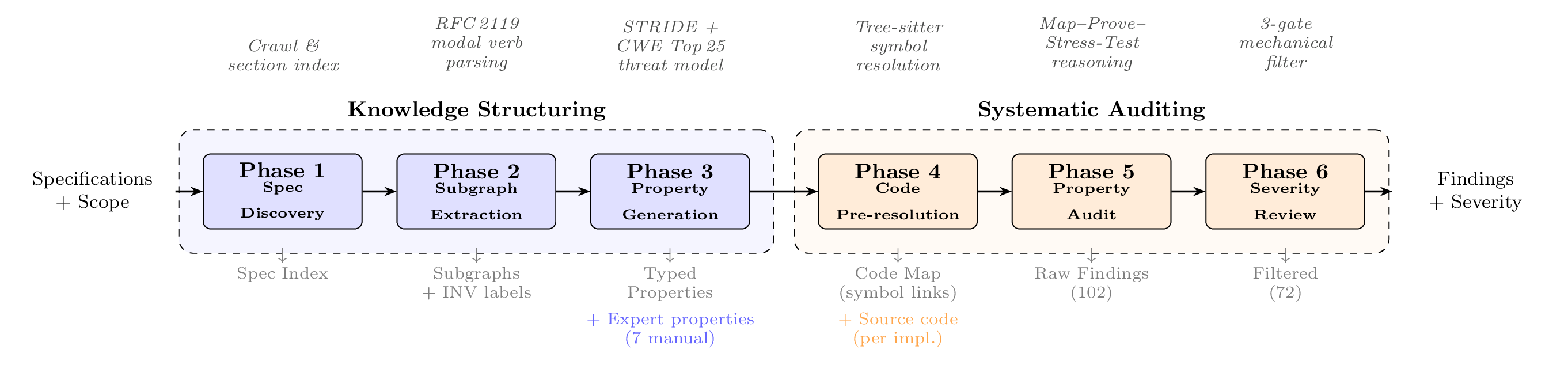
1. 仕様書を集める (Phase 01a)
インターネットからプロジェクトの仕様書やドキュメント (GitHub Issues、スコープ定義など) を自動で探し出します。
2. 仕様書を読み解く (Phase 01b)
集めた仕様書を状態遷移図に変換します。「ユーザーが login を呼ぶ」「その後 process_data が実行される」といった処理の流れを、コンピュータが扱いやすい構造に整理します。図の形式には Mermaid を使っており、各状態には不変条件も付与されます。
3. セキュリティプロパティを導き出す (Phase 01e)
「認証の前に機密データにアクセスされないか」「権限チェックが漏れていないか」といったセキュリティ上の重要な条件を、仕様から自動で生成します。STRIDE (脅威モデリング手法の一種) と CWE Top 25 (よくある脆弱性のリスト) を参考に判定します。この段階で作られた条件を「セキュリティプロパティ」と呼びます。
4. コードのどこを見るか決める (Phase 02c)
セキュリティプロパティを検証するために、実装コードのどこに注目すべきかを事前に特定します。「認証処理は auth.py の authenticate 関数」「データアクセスは database.py の fetch 関数」という具合に、コード上の場所を対応づけておきます。これにより次の監査フェーズのトークン消費を 40〜60% 削減できます。
5. 実際にコードを調べる (Phase 03)
コードを読んで、各セキュリティプロパティが成立するかを論理的に証明してみます。「本当に認証後にのみアクセス可能か」を詳しく調べ、証明できない部分 (proof gap) があれば候補検出として記録します。
6. 誤検出を間引く (Phase 04)
Phase 03 で見つかった候補には、誤検出 (実は問題ではないもの) が混じることがあります。3 つのゲート (デッドコード判定 → 信頼境界チェック → スコープチェック) を順に通し、本当の脆弱性だけを残します。どのゲートで弾かれたかも記録されるため、なぜ誤検出と判断されたかが追跡できます。
もっと詳しく知りたい人へ
- パイプラインの詳細: パイプラインドキュメント
- 証明ベースの監査について: 証明試行ベースの監査
- すぐに試してみたい場合: とりあえず動かしてみる